

Llama进化史
Llama-1 系列
Llama-1是Meta在2023年2月发布的大语言模型,是当时性能非常出色的开源模型之一。它有7B、13B、30B和65B四个参数量版本。Llama-1各个参数量的版本都在超过1T token的语料上进行了预训训练,其中,最大的65B参数的模型在2,048张A100 80G GPU上训练了近21天,并在大多数基准测试中超越了具有175B参数的GPT-3。
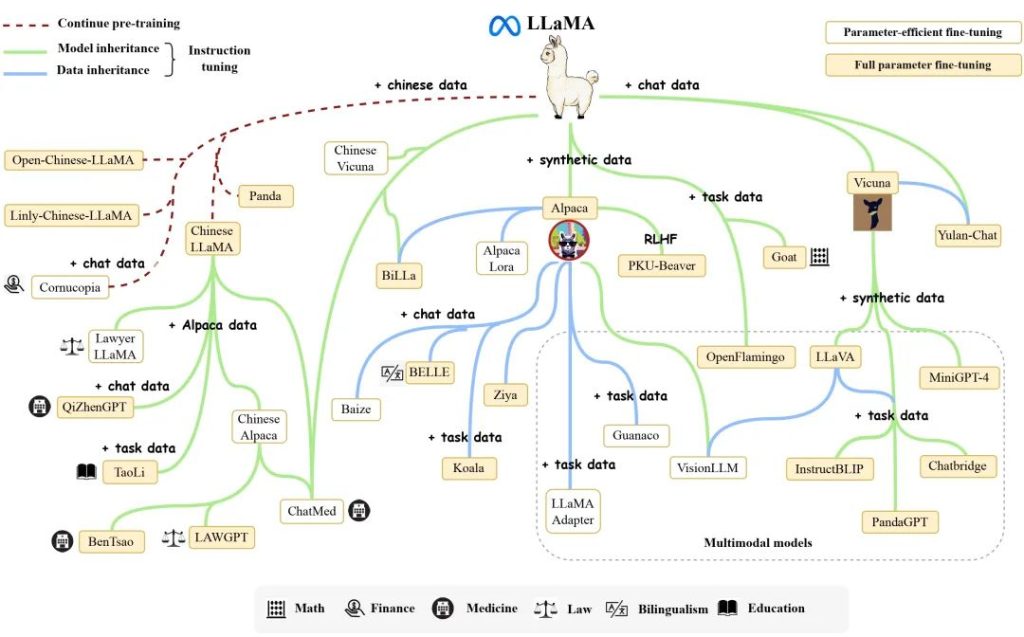
由于模型开源且性能优异,Llama迅速成为了开源社区中最受欢迎的大模型之一,以Llama为核心的生态圈也由此崛起。与此同时,众多研究者将其作为基座模型,进行了继续预训练或者微调,衍生出了众多变体模型(见下图),极大地推动了大模型领域的研究进展。
Llama-2 系列
时隔5个月,Meta在2023年7月发布了免费可商用版本 Llama-2,有7B、13B、34B和70B四个参数量版本,除了34B模型外,其他均已开源。
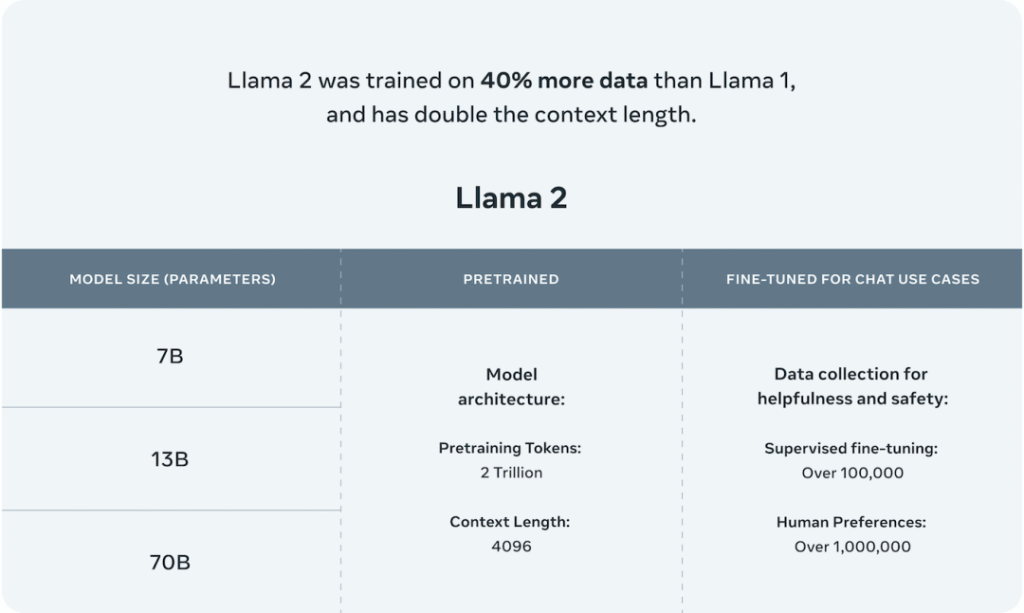
相比于Llama-1,Llama-2将预训练的语料扩充到了 2T token,同时将模型的上下文长度从2,048翻倍到了4,096,并引入了分组查询注意力机制(grouped-query attention, GQA)等技术。
有了更强大的基座模型Llama-2,Meta通过进一步的有监督微调(Supervised Fine-Tuning, SFT)、基于人类反馈的强化学习(Reinforcement Learning with Human Feedback, RLHF)等技术对模型进行迭代优化,并发布了面向对话应用的微调系列模型 Llama-2 Chat。
通过“预训练-有监督微调-基于人类反馈的强化学习”这一训练流程,Llama-2 Chat不仅在众多基准测试中取得了更好的模型性能,同时在应用中也更加安全。
随后,得益于Llama-2的优异性能,Meta在2023年8月发布了专注于代码生成的Code-Llama,共有7B、13B、34B和70B四个参数量版本。

Llama-3 系列
2024年4月,Meta正式发布了开源大模型 Llama 3,包括8B和70B两个参数量版本。除此之外,Meta还透露,400B的Llama-3还在训练中。
相比Llama-2,Llama-3支持8K长文本,并采用了一个编码效率更高的tokenizer,词表大小为128K。在预训练数据方面,Llama-3使用了超过15T token的语料,这比Llama 2的7倍还多。
Llama-3在性能上取得了巨大飞跃,并在相同规模的大模型中取得了最优异的性能。
另外,推理、代码生成和指令跟随等能力得到了极大的改进,使Llama 3更加可控。
模型架构
本节将详细描述Llama的模型架构,包括神经网络的大小、层数、注意力机制等。
目前,主流的大语言模型都采用了Transformer架构,它是一个基于多层自注意力(Self-attention)的神经网络模型。
原始的Transformer由编码器(Encoder)和解码器(Decoder)两个部分构成,同时,这两个部分也可以独立使用。
例如基于编码器的BERT 模型和基于解码器的GPT 模型。
Llama模型与GPT类似,也是采用了基于解码器的架构。在原始Transformer解码器的基础上,Llama进行了如下改动:
- 为了增强训练稳定性,采用前置的RMSNorm作为层归一化方法。
- 为了提高模型性能,采用SwiGLU作为激活函数。
- 为了更好地建模长序列数据,采用RoPE作为位置编码。
- 为了平衡效率和性能,部分模型采用了分组查询注意力机制(Grouped-Query Attention, GQA)。
具体来说,首先将输入的token序列通过词嵌入(word embedding)矩阵转化为词向量序列。然后,词向量序列作为隐藏层状态依次通过𝐿个解码器层,并在最后使用RMSNorm进行归一化。归一化后的隐藏层状态将作为最后的输出。
在每个解码器层中,输入的隐藏层状态首先通过RMSNorm归一化然后被送入注意力模块。注意力模块的输出将和归一化前的隐藏层状态进行残差连接。之后,新的隐藏层状态进行RMSNorm归一化,然后被送入前馈网络层。类似地,前馈网络层的输出同样进行残差连接,作为解码器层的输出。
每个版本的Llama由于其隐藏层的大小、层数的不同,均有不同的变体。接下来,我们将展开看下每个版本的不同变体。
Llama-1 系列
Llama-1 模型架构,详见MODEL_CARD:
https://github.com/meta-llama/llama/blob/main/MODEL_CARD.md

为了更好地编码数据,Llama-1使用BPE 算法进行分词,具体由sentencepiece进行实现。值得注意的是,Llama-1将所有数字分解为单独的数字,并对未知的UTF-8字符回退到字节进行分解。词表大小为32k。
Llama-2 系列
Llama-2 模型架构,详见MODEL_CARD(同上)
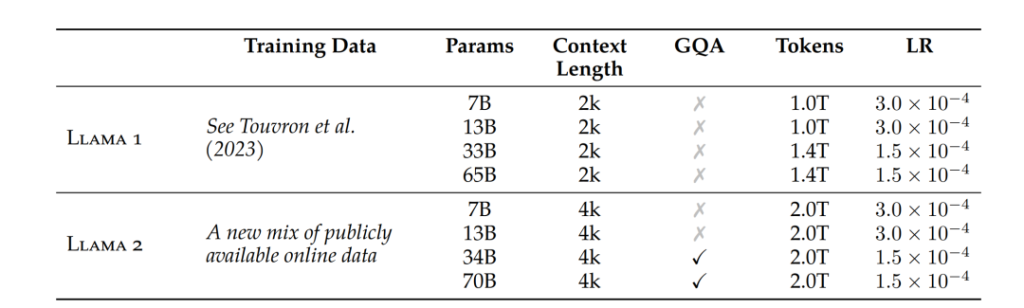
Llama-2使用了和Llama-1相同的模型架构以及tokenizer。与Llama-1不同的是,Llama-2将上下文长长度扩展到了4k,并且34B和70B参数量版本使用了GQA。
Llama-3 系列
Llama-3 模型架构,详见MODEL_CARD:
https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md

与Llama 2相比,Llama-3将tokenizer由sentencepiece换成了tiktoken,这与GPT4 保持一致。同时,词表大小由32k扩展到了128k。另外,为了提高模型效率,Llama-3 8B和70B都采用了GQA。同时上下文长度也扩展到了8k。
Leave a Reply to humble_gamong Cancel reply