

自从GPT发布以来,大模型异常火爆,学者们都想尽一切方法去将大模型投入应用之中。 当下很多大语言模型虽然说可以不做调试直接进行使用, 但是在许多具体的应用场景中还是在微调过后的稳定性与效果更好, 也就是在论文中常常出现的finetune。 在小模型流行的时期, finetune不会是大问题。 但在大模型流行的时期, finetune是个相当棘手的难题。 追根到底还是因为现在大模型的参数量动辄10B起步, 而且训练的代价非常昂贵,即使是刚刚满足finetune也仍然对算力和计算资源有非常高的要求(finetune仅仅是训练所需的的步数相对较少,因此它对显存等计算资源的使用没有减少)。 没有上百个G的显存是无法实现模型参数的微调的的, 也就是说这对普通人的门槛实在太高了。
以此看来,高效的finetune方式就显得格外重要了,而LoRA就是这样一种高效的finefune方法。
LoRA 背景知识
受限于 GPU 内存,在训练的过程中同时更新对应模型的权重,其成本会非常高昂。
假设我们现在需要微调一个含有7B 参数量的大语言模型,现用一个权重矩阵 W来表示。在反向传播的过程中,大语言模型需要重新学习一个 ΔW 矩阵,目的用于更新初始的权重分配,从而让损失函数的值达到最小。
更新后的如下:W_updated = W + ΔW。
如果说权重矩阵 W 本身就含有 7B 个参数,那么使得权重更新的矩阵 ΔW 也会包含 7B 个参数,因此计算矩阵 ΔW 是非常消耗计算和现有内存的。
由 Edward Hu 等人提出的 LoRA 就是将权重变化的部分 ΔW 分解成低秩来表示。确切地说,它甚至不需要去显示计算 ΔW。相反的,LoRA 其实是在训练的同时学习 ΔW 的分解表示,正如下图所示,而这就是 LoRA 节省算力的一大原因。
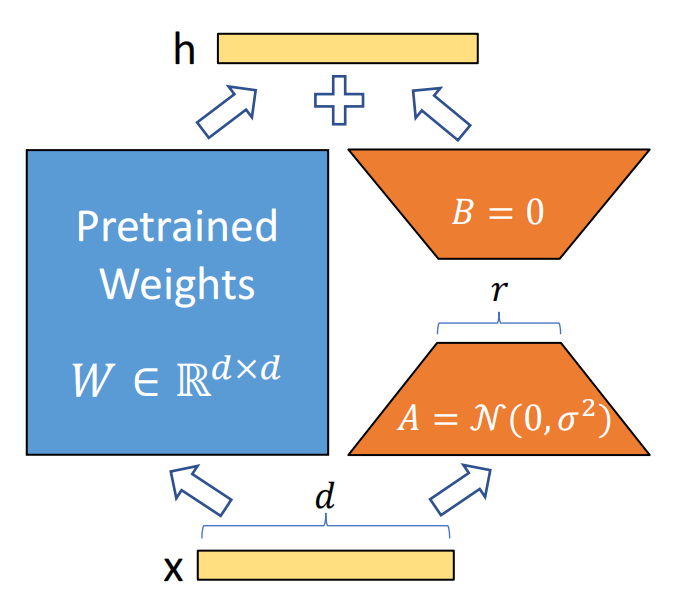
LoRA原理
LoRA的原理非常简单, 如上一张图片所展示的, 从图片上已然能够清晰地理解到大概的原理的。 通俗来解释一下:大语言模型其实都是过参数化的, 所以当它被用于特定的任务时, 其实只有一小部分的参数在起到主导作用。 也就是说即使参数的矩阵维度很高, 也可以用低维矩阵来把它分解近似。其实这个想法和矩阵的特征向量, 主成分的分析, 还有压缩感知等方法有着异曲同工之妙。
具体做法就是在网络中增加一个旁路结构,旁路就是A和B两个矩阵相乘。 A矩阵的维度大小是D*R, B 矩阵的维度大小是R*D, 其中R<<D, 所以一般性情况下R取1,2,4,8就可以了。如此一来这个旁路的参数量将会远远小于原来网络的参数W。在LoRA训练的时候, 我们先“冻结”原来网络的参数W, 只训练旁路的参数A和B。 而由于A和B的参数总量远远小于W, 那么这个时候训练所需要的显存开销就约等于推理时长的开销。 而对于采用了Adam的优化器来说, 它所需要的显存就约等于全参数finetune的1/3, 极大幅度地减小了训练微调的消耗。
在论文中,作者的实验也证明了这一点。 在GPT-3 175B的finetune当中, 采用了LoRA微调方法的显存的消耗从1.2TB 直接降低到了350GB, 约为原来的三分之一
需要注意的是, LoRA微调实际上并没有改变原有的预训练模型的参数,而只不过是针对某些特定的任务微调出了一些新的少量的参数, 而这些新的参数如果想要与原来就有的预训练的参数来配合使用(在实际使用的时候, 通常都是把旁路的参数和原来的参数直接合并, 也就是数学上的参数相加, 这样就不会增加推理的时间)。这是非常方便的,而且针对不同要求的任务, 我们都可以训练出自己的LoRA参数, 然后再与原来的预训练参数结合, 做成插件式的应用。 这就是最近大火的SD + LoRA。目前Civitai上有上万LoRA的模型, 并且还在以一种惊人的速度迅速增加。
优势分析
LoRA的主要优点之一就是他们的效率。通过使用更加少的参数,LoRA明显地降低了模型训练过程中的计算复杂性以及显存的使用量。这可以让我们在可消费级的GPU上面来训练大语言模型,并且可以便利地将我们训练好的LoRA权重(以兆为单位)分发给其他人。
此外,LoRA微调方法还可以提升模型的泛化性。通过限制模型的复杂度,可以防止在训练的数据集有限的场景下的过拟合现象;由于LoRA保留了初始模型的能力,因此在处理一些新的,未见过的数据时,它会更具有弹性。
最后,LoRA还可以无缝地集成到现有的神经网络架构中。这种集成允许以最小的额外训练成本对预训练模型进行微调和调整,使其非常适合迁移学习应用。
Leave a Reply